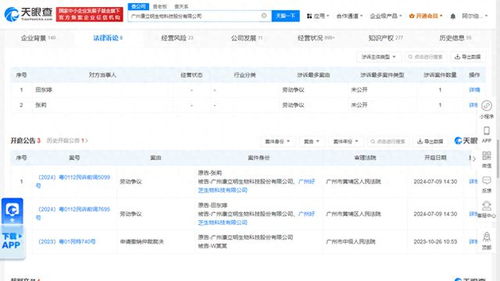
廣州康立明生物科技有限公司,一家專注于科技推廣和應(yīng)用服務(wù)的生物技術(shù)企業(yè),近期卷入勞動爭議風(fēng)波。案件于7月9日在廣州市黃埔區(qū)人民法院正式開庭審理,引發(fā)了業(yè)界和公眾的廣泛關(guān)注。
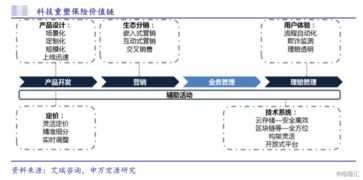
據(jù)了解,該勞動爭議涉及員工權(quán)益問題,可能包括薪酬支付、勞動條件或合同履行等方面的糾紛。作為一家科技推廣和應(yīng)用服務(wù)公司,康立明生物科技在生物技術(shù)領(lǐng)域具有一定影響力,但此次事件暴露了企業(yè)在人力資源管理上的潛在短板。
在當(dāng)前的法治環(huán)境下,勞動爭議的妥善處理對于維護(hù)勞資雙方利益至關(guān)重要。法院的審理將為類似案例提供參考,同時也提醒其他科技企業(yè)重視內(nèi)部管理,確保遵守勞動法規(guī)。
隨著案件的進(jìn)展,我們將持續(xù)關(guān)注后續(xù)發(fā)展,并呼吁企業(yè)強化社會責(zé)任,促進(jìn)和諧勞動關(guān)系,以支持科技創(chuàng)新與應(yīng)用的可持續(xù)發(fā)展。